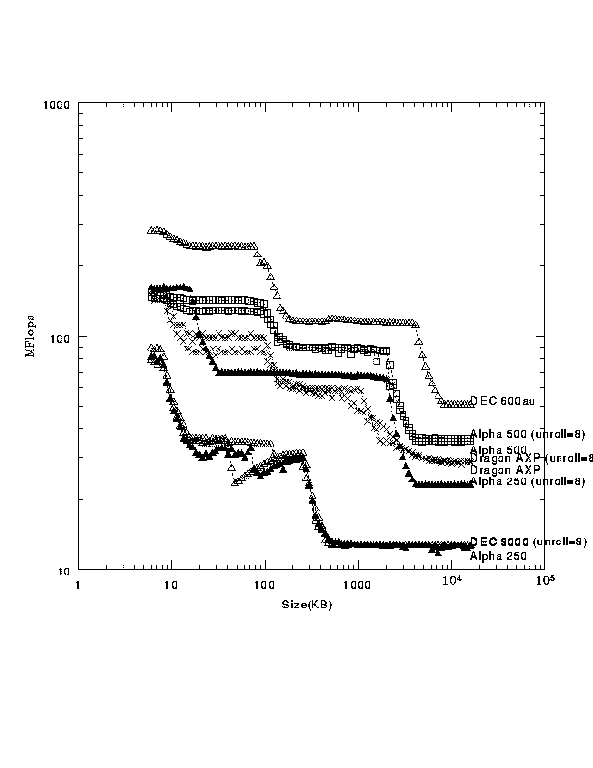
これは、姫野龍太郎さん(日産自動車株式会社、総合研究所・車両研究所)の かかれたメモリからデータの供給能力とCPUの積・和計算の性能を計るようにかかれた cache_test1というベンチマークプログラムの結果です。コアとなる部分は
dimension a(imax,m)
s0=0.0
s1=0.0
do i=1,m
s0=s0+a(1,i)*a(2,i)+a(3,i)*a(4,i)
s1=s1+a(5,i)*a(6,i)+a(7,i)*a(8,i)
enddo
s=s0+s1
で、このmを増加させて配列の容量を増やしていった時に計算に要する時間が
どのように変化するかを見たものです。
ここではDEC Alpha 3000 (21064 133MHz)、 DEC AlphaStation 250/266 (21064A 266MHz)、 DEC AlphaStation 500/333 (21164 333MHz)、 Dragon AXP 5/300 (21164 300MHz)について調べてあります。
それぞれループ・アンローリング(-uroll 8)をおこなった場合と、 行なわなかった場合のMFLOPS値が配列a(imax,m)の大きさを横軸にとって 書かれています。
配列が大きくなり1次キャッシュ、2次キャッシュ、3次キャッシュと溢れるたびに MFLOPS値が階段状に悪くなることがわかります。 アンローリングを行なった結果を見ると、MFLOPS値は必ずしもCPUのクロックの 速さだけで決まっていないことがわかります。
興味のある方はソースを見て下さい。