|
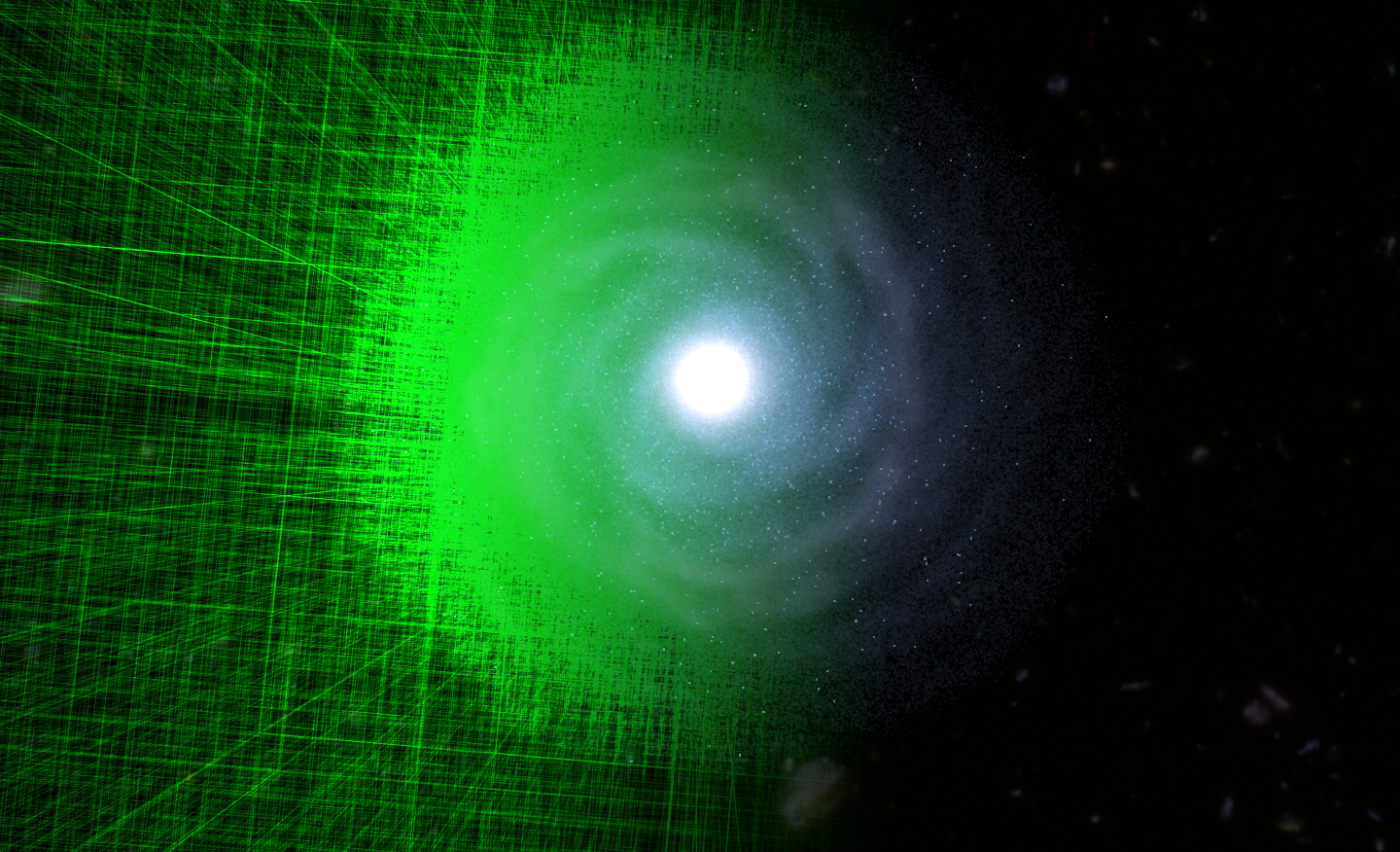
| 図1: 本研究のシミュレーションで計算された銀河の姿。左半分の緑色の部分は、重力計算のための領域分割を可視化したもの。(クレジット:Bédorf et al. (2014)) |
オランダ・ライデン大学のユルン・べドルフ氏、シモン・ポルテギースズワート氏、国立天文台理論研究部の藤井通子 特任助教(国立天文台フェロー)らの研究チームはアプリケーション「Bonsai」を開発し、18600台のGPU1を用いた計算により、これまでで最大規模の天の川銀河進化の数値シミュレーションを成功させました。計算に用いた粒子数は約2400億であり、この計算により初めて、天の川銀河の星の観測データと直接比較可能なシミュレーションデータを得ることができるようになりました。
さらにこのシミュレーションでは使用したGPUの数に対して単精度2で世界最速の実効性能3 24.77Pflops4 (1秒間に2.477京回の計算)を達成しました。このシミュレーションの性能と科学的意義が評価され、2014年のゴードン・ベル賞5のファイナリストとして選出されました。
|
|
| 図1: 本研究のシミュレーションで計算された銀河の姿。左半分の緑色の部分は、重力計算のための領域分割を可視化したもの。(クレジット:Bédorf et al. (2014)) |
| ユルン・べドルフ | (ライデン大学、オランダ国立情報工学・数学研究所) |
| エフゲニー・ガブロフ | (SURFsara) |
| 藤井通子 | (国立天文台 理論研究部 特任助教、国立天文台フェロー) |
| 似鳥啓吾 | (理化学研究所 計算科学研究機構 コデザイン推進チーム 研究員) |
| 石山智明 | (筑波大学 計算科学研究センター 研究員) |
| シモン・ポルテギースズワート | (ライデン大学) |
Jeroen Bédorf, Evghenii Gaburov, Michiko S. Fujii, Keigo Nitadori, Tomoaki Ishiyama, Simon PortegiesZwart, “24.77 Pflops on a Gravitational Tree-Code to Simulate the Milky Way Galaxy with 18600 GPUs”, 2014 ACM/IEEE conference on Supercomputing (SC14), New Orleans, Louisiana, USA, Nov. 2014
http://dl.acm.org/citation.cfm?id=2683600
私たちの棲む太陽系は、天の川銀河の銀河円盤の中に存在しています。そのため銀河円盤を常に横から見ている状態にあり、天の川銀河がどのような姿をしているのかを直接見ることができません。しかし、銀河内の星の位置やその速度を正確に測ることで、棒状構造や渦巻き腕のような銀河の構造を知ることができます。2013年に打ち上げられたヨーロッパの位置天文宇宙望遠鏡「Gaia」(ガイア)6や、今後打ち上げが予定されている日本の位置天文観測衛星「JASMINE」(ジャスミン)7によって、まもなく天の川銀河内の星の位置と速度がこれまで以上に正確にわかってきます。しかしこの観測データを読み解くためには、星の運動が銀河のどのような構造を反映しているかを知っておく必要があります。これには銀河の構造と星の運動の関係を直接知ることができるシミュレーションが重要な役割を果たします。観測とシミュレーションと合わせることによって初めて、天の川銀河の構造とそのメカニズムが明らかになるのです。

|
| 図2: ハッブル宇宙望遠鏡で観測された渦巻銀河UGC12158。天の川銀河はこの銀河に似た形をしていると考えられている。中心付近に棒状の構造があり、その周りに渦巻き腕が取り巻いている。(クレジット:ESA/Hubble & NASAを改変 ) |
実際の天の川銀河を構成する星は2000億~4000億個と言われています。シミュレーションと観測を比較するためには、本来、膨大な数の星や銀河を取り囲むダークマター8の間に働く重力を計算し、個々の星の運動を導きださなければなりません。これには莫大な計算能力を持ったスーパーコンピュータが必要になります。これまでのシミュレーションでは、1000個程度の星を1つの粒子に置き換えるなどの近似を用いた計算が行われて来ました。しかし、このようなシミュレーションでは、観測データとの直接比較はできません。来るべき位置天文衛星のデータを理解するためには、より現実的なシミュレーションが必要となるのです。
このような問題に対し研究チームは、スイス国立スーパーコンピュータセンターのPiz Daint9とアメリカ・オークリッジ国立研究所のTitan10という、CPU11に加えてGPUを搭載したスーパーコンピュータを用いて、これまでで最大規模の天の川銀河の進化シミュレーションを行いました。シミュレーションに用いたGPUの最大の数は、Titanに搭載された18600台になります。これほど多くのGPUを使い、かつ効率よく計算を行うには、様々な工夫が必要となります。一般に、使用するGPUの数が多くなるほど、GPU間のデータ通信に時間がかかるようになり、計算全体の効率は落ちます。つまり2倍の数のGPUを使っても、計算速度は2倍にはならず、それよりも遅くなってしまいます。今回、研究チームが開発したアプリケーション「Bonsai」では、シミュレーションの中でもっとも計算時間のかかる星と星の間に働く重力の計算を全てGPUで行い、通信とそれに関わる計算をCPUで行うことで、GPUとCPUを同時にフル活用できるように工夫しました。そのため、GPUは通信を待つことなく計算を続けることができ、多くのGPUを用いても高い計算効率を維持することができたのです。18600台のGPUを用いて行われた計算の実効性能は、単精度で24.77Pflops(1秒間に2.477京回計算)を達成しました。これは、現在公表されている中では最高の値です。
今回の天の川銀河のシミュレーションで用いた星とダークマター粒子の数は合わせて最大約2400億個、星のみでは約200億個です。これは従来の計算より数百倍から数千倍多くの粒子を用いた、まさしく世界で最大規模の天の川銀河シミュレーションとなりました。天の川銀河の姿を知るためには、このシミュレーションで作られた天の川銀河を疑似観測して、実際の観測データと照らし合わせる事が必要になります。Gaiaなどで観測できる実際の天の川銀河の星の数が約10億天体ほどであることを考えると、今回の規模の計算で、初めてシミュレーションから得られた星の数が実際の天の川銀河の観測データの星ひとつひとつと比較できる数になりました。
| 動画:シミュレーションの可視化動画(クレジット:SURFsara, Bédorf et al. 2014 and NVIDIA) |

|
|
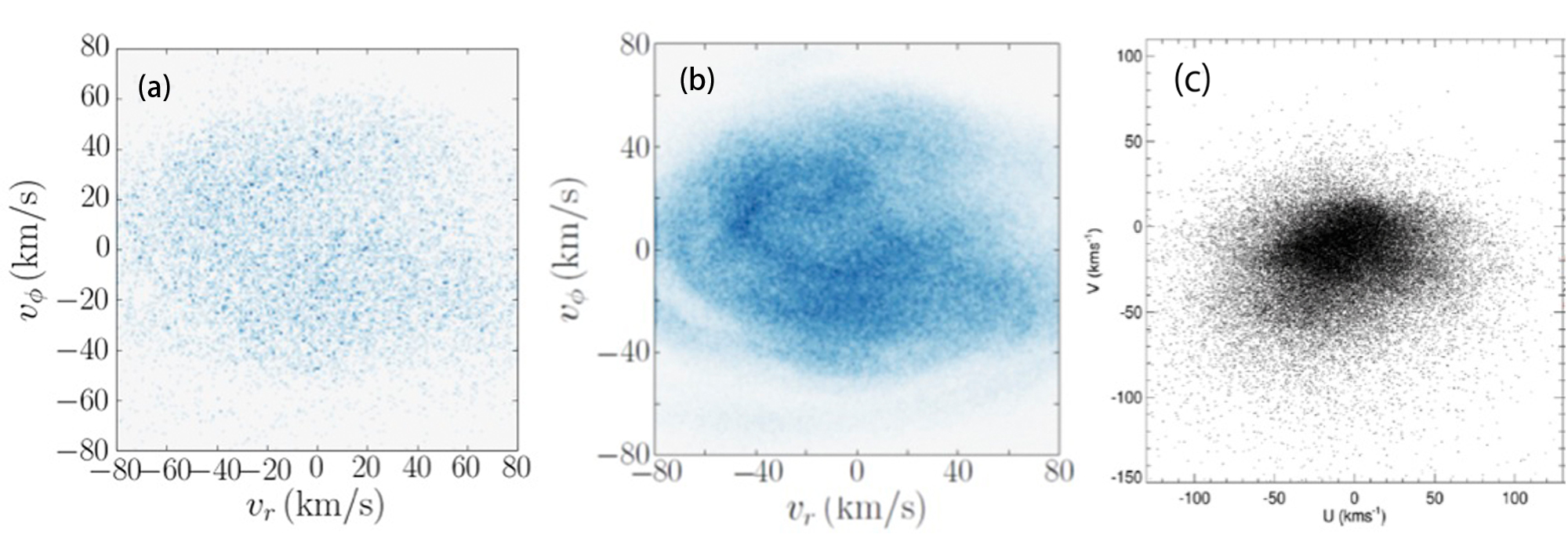
| 図3: (上)シミュレーションによって再現された天の川銀河を可視化したもの。星を青や白で表している。ダークマター粒子はここでは表示していない。渦巻き腕などの銀河の構造が見えている。(クレジット: SURFsara, Bédorf et al. 2014 and NVIDIA)(下)シミュレーションデータを疑似観測して得られる星の速度図(a,b) と観測から得られる星の速度図(c)。横軸が銀河中心からの半径方向の速度、縦軸が銀河回転方向の速度を表す。本研究ではいくつかの条件で計算をしており、(b)では500億粒子(従来の計算の500倍の粒子数)で計算した結果を示している。以前までのシミュレーションの結果(a)に対して、本研究の結果(b)は多くの星の情報を得ることができている。さらに(b)では銀河の構造を反映した速度のパターンを見て取ることができる。(クレジット:図(a,b): Bédorf et al. (2014)、図(c): T. Antoja et al., “Kinematic groups beyond the solar neighbourhood with RAVE”, MNRAS(2012), 426(1):L1-L5, Figure 2.(a)より) |
今回の研究で行われたシミュレーションは、そのパフォーマンスの良さと、多くのGPUを使って効率よく計算するための手法、そして科学的意義が評価され、2014年のゴードン・ベル賞ファイナリストとして選出されました。アメリカ・ニューオーリンズで開催されるハイ・パフォーマンス・コンピューティング(高性能計算技術)に関する国際会議SC14にて、日本時間11月20日にファイナリスト選出者らによる最終プレゼンテーションが行われ、日本時間11月21日に受賞者が決定します。
国立天文台理論研究部・特任助教(国立天文台フェロー)の藤井通子氏はこの研究において、シミュレーションを行う銀河のモデル作りと計算結果の解析を担当しました。天の川銀河を再現するようなモデルにはどのようなパラメータ設定が最適か、これまでの藤井氏自身の研究成果も踏まえて選びました。また現在は、計算結果からシミュレーションが正しく行われているかを評価し、実際の天の川銀河の観測と比較していく上で必要となるデータの解析をおこなっています。さらにこの研究には日本から、理化学研究所計算科学研究機構の似鳥啓吾研究員と筑波大学計算科学研究センターの石山智明研究員がアプリケーション開発で協力をしました。オランダからは、チームリーダーのシモン・ポルテギースズワート(ライデン大学)、ユルン・ベドルフ(ライデン大学/オランダ国立情報工学・数学研究所)、エフゲニー・ガブロフ(SURFsara)が協力しました。
 藤井通子 国立天文台 理論研究部特任助教(国立天文台フェロー) |
藤井氏は今回ゴードン・ベル賞にファイナリストに選出されたことについて、このように語ります。 「私は昨年9月までオランダのライデン大学に所属しており、昨年から、今回のプロジェクトに参加しています。今回、2回目の挑戦でファイナリストに残ることができました。オランダのスーパーコンピュータは日本と比べると規模が小さく、いつでも大規模なスーパーコンピュータを使ってコードのテストをできるわけではありません。そこで、筑波大学のGPUスパコン「HA-PACS」12や、国立天文台のCPUスパコン「アテルイ」13も利用しながらコード開発を続けてきました。最終的に、最も大規模な計算を行ったTitanも、利用できる時間が非常に限られた中での挑戦でした。そのような不利な環境を乗り越えてのファイナリスト選出なので、非常に嬉しく思います。今後、データ解析という大変な仕事が待っていますが、天の川銀河の研究にとって大きな一歩となる結果を出せるよう頑張ります。」 |
今回のシミュレーションでは、これまでと比べ、非常に多くの数の星を扱っているため、観測とのより詳細な比較が可能となりました。今後、昨年打ちあげられたGaiaのデータとシミュレーションで得られた結果を比較していくことで、天の川銀河の棒状構造や渦巻き腕の位置や大きさ、またそれらの構造の進化過程が明らかになると期待されています。さらに、このシミュレーションによって作られる天の川銀河は、観測から直接見ることができない天の川銀河の構造の解明を可能にしてくれます。
今回のシミュレーションで得られたデータの解析は現在進行中です。シミュレーションと観測が解き明かす天の川銀河の姿にご期待ください。
本研究は,文部科学省HPCI戦略プログラム5「物質と宇宙の起源と構造」および計算基礎科学連携拠点の協力により実施されました.
用語解説(本文注釈)
1) GPU(Graphics Processing Unit):コンピュータの中で、画像演算処理を行うための専用のプロセッサ。画像演算処理のためには、浮動小数演算を行う必要があり、そのためにGPUには多数の演算器が用意されている。
2) 単精度:単精度浮動小数点数。情報処理におけるコンピュータの数値表現の形式の一つで,1つの数値を32ビットで表現するもの。表現できる値の範囲は-3.40282×1038~3.40282×1038で、精度は6桁である。これに対して64ビットで実数を表すものを倍精度浮動小数点数とよび、表現できる値の範囲は-1.79769×10308~1.79769×10308であり、精度は15桁である。
3) 実効性能:理論性能であるピーク性能に対して、あるアプリケーションを実行したときの計算性能。計算機の実質的な性能とされている。
4) Pflops (ペタフロップス、Peta Floating-point Operations Per Second):flopsは1秒間に行った浮動小数点数演算の数で、コンピュータの性能を表す指標の一つ。P(ペタ)は1015(1千兆)倍。
5) ゴードン・ベル賞:ゴードン・ベル賞とは、計算機設計者として有名なアメリカのゴードン・ベル氏により、並列計算機技術開発の促進のため1987年に創設された賞。この賞は実用的な並列計算で高い性能を達したことに対して与えられる。単に達成した演算速度ではなく、科学技術研究に有用な計算の高速化を、並列化や最新のハードウエアの利用、計算法の改良といった総合的なアプローチによって実現したことが評価される。
6) 位置天文宇宙望遠鏡Gaia(ガイア):2013年12月に欧州宇宙機関(ESA)によって打ち上げられた観測機。天の川銀河の恒星について位置を測定し、分光観測によって星の視線速度をはかるための専用望遠鏡。可視光で約20等級までの明るさの星を観測し、約10億の恒星について位置と速度のデータを取得することを目標としている。
7) JASMINE(ジャスミン)衛星:国立天文台が2020年代に打ち上げを計画している赤外線位置天文観測衛星。可視光では観測が難しい3万光年先の天の川銀河の中心に近い、バルジと呼ばれる星が混んだ領域を赤外線で観測し、星の位置と速度を測ることで、天の川銀河の地図をつくること目的としている。
8) ダークマター:重力相互作用だけが働く物質で、素粒子としての正体は解明されていない。宇宙初期に存在したダークマターの密度揺らぎが重力相互作用により成長して、至るところにさまざまなサイズの天体を形成し、その中で陽子や中性子といった通常物質を集め、現在の宇宙で観測される銀河のような構造を作ってきたという理論「低温ダークマターモデル」がある。これが、宇宙の構造形成を記述する標準的なモデルとして広く受け入れられている。
9) Piz Daint(ピーツ・ダイント):スイス国立スーパーコンピュータセンターが運用する、ハイブリッドCray XC30システムのスーパーコンピュータ。 CPUとGPUを組み合わせた異種混合クラスタスパコンに分類される。理論演算性能は7.787 Pflops(倍精度)。2014年6月に発表されたスーパーコンピュータランキングTop 500で6 位となった。
10) Titan(タイタン):オークリッジ国立研究所が運用する、Cray XK7システムのスーパーコンピュータ。CPUとGPUを組み合わせた異種混合クラスタスパコンに分類される。理論演算性能は27.1Pflops(倍精度)。2014年6月に発表されたスーパーコンピュータランキングTop 500で2位となった。
11) CPU(Central Processing Unit):中央演算処理装置。コンピュータを構成する部品のひとつで、プログラムに従って演算・計算を行う電子回路や演算ユニットのこと。コンピュータのまさしく頭脳にあたる部分である。
12) HA-PACS(Highly Accelerated Parallel Advanced system for Computational Sciences):筑波大学計算科学研究センターが運用する、GPU搭載の超並列演算加速器型スーパーコンピュータ。理論演算性能は1.166Pflops(倍精度)。
13) アテルイ:国立天文台 天文シミュレーションプロジェクトが運用する天文学専用スーパーコンピュータ。Piz Daintと同じCray XC30だが、GPUは搭載されずCPUのみで構成されている。今回の研究に用いられた当時の理論演算性能は502Tflops(倍精度,2014年8月まで)。
問い合わせ窓口
国立天文台 理論研究部 広報担当
福士比奈子
電話:0422-34-3836
Email:fukushi.hinako ATM nao.ac.jp (ATM→@)
関連リンク
ゴードン・ベル賞ファイナリスト(英語)
http://sc14.supercomputing.org/blog/finalists-compete-coveted-acm-gordon-bell-prize
本研究チーム 最終プレゼンテーションについて(英語)
http://sc14.supercomputing.org/schedule/event_detail?evid=gb108
独立行政法人 理化学研究所 計算科学研究機構
筑波大学計算科学研究センター
HPCI戦略プログラム分野5「物質と宇宙の起源と構造」